Sichtbardort,woMenschenfragen.
Wenn ein Kunde ChatGPT, Perplexity oder Google AI Overviews befragt, tauchen in der Antwort drei bis fünf Quellen auf. Welche dort erscheinen, entscheidet sich nicht im Ranking-Algorithmus, sondern in der Architektur des Inhalts. SnapSite baut diese Architektur: Entity-Verankerung, strukturierte Daten, zitierfähige Formate und Retrieval-Optimierung, damit Sprachmodelle euren Inhalt bevorzugt heranziehen.
Drei Ebenen, eine Strategie.
Google Search, Google AI Overviews und LLM-basierte Antwort-Engines folgen unterschiedlichen Logiken. Wer in allen drei Schichten präsent ist, baut Autorität auf, die kein einzelner Kanal allein liefern kann.
Keywords, Backlinks, Core-Web-Vitals. Ranking basiert auf Seitenrelevanz im Verhältnis zur Suchanfrage. Klick-Rate sinkt, sobald Nutzer direkt in KI-Antworten landen.
Google zieht Quellen aus dem Web, synthetisiert eine Antwort und verlinkt ausgewählte Seiten. Gewichtet werden semantische Dichte, Schema-Markup und Autoritätssignale.
Retrieval-Augmented Generation zieht Dokumente in Echtzeit aus dem Web. Tokenisierung, Embedding-Distanz und Recency-Signale entscheiden, welche Fragmente in der Antwort landen.
Markewerden,nichtnurWebseite.
Sprachmodelle denken in Entitäten, nicht in URLs. Eine Entität ist eine benannte Einheit mit verifizierbaren Attributen, die in mehreren unabhängigen Quellen konsistent auftaucht. Wikidata-Eintrag, Google Knowledge Panel, sameAs-Schema, Erwähnungen in Fachpublikationen und Branchenverzeichnissen: wer dort verankert ist, wird von Modellen erkannt und bevorzugt zitiert.
Der Unterschied zur klassischen Linkbuilding-Logik: Nicht die Anzahl der Verweise zählt, sondern die Diversität der Quelltypen. Ein Wikidata-Eintrag, ein Branchenverzeichniseintrag und ein redaktioneller Pressehinweis sind stärker als zehn Gastbeiträge auf thematisch ähnlichen Blogs.
Daten,dieModellelesen.
LLM-Parser lesen die Datenebene, bevor sie Fließtext verarbeiten. JSON-LD mit Organization-Schema, sameAs-Verknüpfungen und Person-Schema für Autoren ist der direkteste Weg, Modellen beizubringen, wer ihr seid und welche Themen ihr belegt.
{ "@context": "https://schema.org", "@type": "Organization", "name": "Ihr Unternehmen", "url": "https://ihr-unternehmen.de", "sameAs": [ "https://de.wikipedia.org/wiki/Ihr_Unternehmen", "https://www.wikidata.org/wiki/Q123456", "https://www.linkedin.com/company/ihr-unternehmen", "https://www.crunchbase.com/organization/ihr-unternehmen" ], "founder": { "@type": "Person", "name": "Vorname Nachname", "sameAs": "https://www.linkedin.com/in/vorname-nachname" }, "knowsAbout": [ "Premium-Dienstleistung", "Branchenspezifisches Thema A", "Branchenspezifisches Thema B" ]}LLMs gewichten strukturierte Daten anders als klassische Crawler: sameAs-Verknüpfungen signalisieren Entitätskonsistenz über Quellen hinweg. knowsAbout definiert topische Kompetenz explizit. Beides beeinflusst, ob ein Modell euren Namen in einer Empfehlung nennt.
Formate, die zitiert werden.
Welche Inhalte ein Sprachmodell in eine Antwort zieht, hängt nicht nur davon ab, was gesagt wird, sondern wie es verpackt ist. Diese drei Formate erzielen konsistent höhere Citation-Raten.
Nummerierte Listen
LLMs extrahieren Schritte und Rankings bevorzugt aus geordneten Listenformaten. Ein nummerierter Block ist tokenisierbar ohne Kontextverlust.
Klare Definitionen
Definitionen im Format 'X ist Y' sind ideal für Embedding: der Satz trägt seine Bedeutung allein, ohne dass umliegender Kontext mitgelesen werden muss.
Vergleichs-Tabellen
Tabellen werden von Parsern als strukturierte Datenpunkte erkannt. Perplexity und ChatGPT zitieren Tabellen-Vergleiche überdurchschnittlich häufig in Empfehlungsantworten.
WoInhaltlandet.
RAG (Retrieval-Augmented Generation) ist die Technik hinter Perplexity, ChatGPT-Search und Google AI Overviews. Sie zieht Dokumente aus dem Web und synthetisiert daraus Antworten. Welche Fragmente eines Dokuments in die Antwort fließen, entscheidet Tokenisierung, Embedding-Distanz und Aktualitätssignale.
Tokenisierung
Sprachmodelle zerlegen Texte in Tokens. Kurze, klare Absätze ohne Verschachtelung bleiben beim Tokenisieren semantisch intakt. Schachtelsätze verlieren Bedeutung beim Schneiden.
Snippet-Länge
RAG-Systeme ziehen Snippets einer definierten Länge. Wer zu lange Absätze schreibt, riskiert, dass das relevante Fragment in der Mitte eines abgeschnittenen Chunks landet und nicht mehr zitiert wird.
Recency-Signale
Publication-Date und Last-Modified im HTML-Head sowie im Schema-Markup beeinflussen, wie aktuell ein Dokument eingestuft wird. Ältere Inhalte ohne Aktualisierungsdatum werden seltener in zeitnahen Antworten zitiert.
Embedding-Distanz
Retrieval-Systeme berechnen die semantische Nähe zwischen Suchanfrage und Dokument. Je spezifischer und thematisch fokussiert ein Absatz, desto geringer die Embedding-Distanz zur passenden Anfrage.
Was ein Modell fragt.
AEO dreht die Keyword-Logik um: statt zu fragen, was Nutzer tippen, fragen wir, welche Prompts ein Modell über eure Kunden formulieren würde. Jede Seite sollte eine Antwort auf einen dieser Prompts sein.
// typische LLM-Prompts, die zu eurer Branche formuliert werden. Eure Seiten sollten jede davon beantworten.
Quellen, die tragen.
LLMs bewerten Quellen nach EEAT-Logik: Expertise, Erfahrung, Autorität, Vertrauenswürdigkeit. Diese vier Faktoren sind die Hebel für nachhaltige AI-Visibility.
EEAT-Signale für KI
Author-Schema mit Person-Typ, Qualifikations-Feldern und LinkedIn-sameAs signalisiert Expertise. LLMs bevorzugen Inhalte, die einer benennbaren, überprüfbaren Person zugeordnet werden können.
Publikations- und Änderungsdaten
datePublished und dateModified im ArticleSchema und im HTML-Head sind direkte Recency-Signale für RAG-Systeme. Ohne diese Felder stufen Modelle den Inhalt als potentiell veraltet ein.
Hochwertige Backlinks
Nicht die Anzahl der Links zählt, sondern die thematische Autorität der verlinkenden Domäne. Ein Eintrag in einem Fachverzeichnis überwiegt zehn generische Verweise.
Unlinked Mentions
Namentliche Erwähnungen ohne Hyperlink werden von LLMs als Co-Citation erkannt. Wer in Fachartikeln, Foren und Verzeichnissen genannt wird, ohne verlinkt zu sein, baut trotzdem Autorität auf.
Vier Phasen, keine Hektik.
AI-Visibility ist kein Sprint. Entitätsstatus und Citation-Autorität bauen sich in Schichten auf. Wer das in einem Monat verspricht, versteht entweder die Mechanik nicht oder rechnet mit eurer Ungeduld.
Diagnose
Welche Modelle zitieren wen heute.
Wir testen ein Set von Queries durch ChatGPT, Perplexity und Google AI Overviews und messen, wie oft und in welchem Kontext eure Marke erscheint. Ergebnis: ein dokumentiertes Baseline-Bild, das zeigt, wo ihr steht und welche Wettbewerber bevorzugt werden.
Anker
Entity etablieren, Knowledge-Graph anschließen.
Wikidata-Eintrag, Google Knowledge Panel, sameAs-Schema und Branchenverzeichnis-Einträge. Dieser Schritt macht euch zu einer erkennbaren Entität für Sprachmodelle, nicht nur zu einer Webseite. Ohne Entitätsstatus keine stabile Citation-Rate.
Distribution
Content in Formaten ausspielen, die zitiert werden.
Überarbeitete Sales-Seiten in zitierfähige Absätze, FAQ-Blöcke und Definitions-Pattern. Outreach auf gewichteten Quell-Domains: Fachpublikationen, kuratierte Verzeichnisse, redaktionelle Erwähnungen. Jede Platzierung mit URL und Datum dokumentiert.
Monitoring
Quartalsweise prüfen, ob Citation-Score steigt.
Wöchentliche Probe-Query-Läufe, Monatsbericht mit Citation-Score-Verlauf und AI-Referrer-Traffic. Quartalsweise Strategiegespräch: Was hat gewirkt, was wird angepasst, welche neuen Themen belegt werden sollen.
Acht Fragen, acht Antworten.
Kundenprojekte
Passende Beispiele
So sieht das in echt aus.
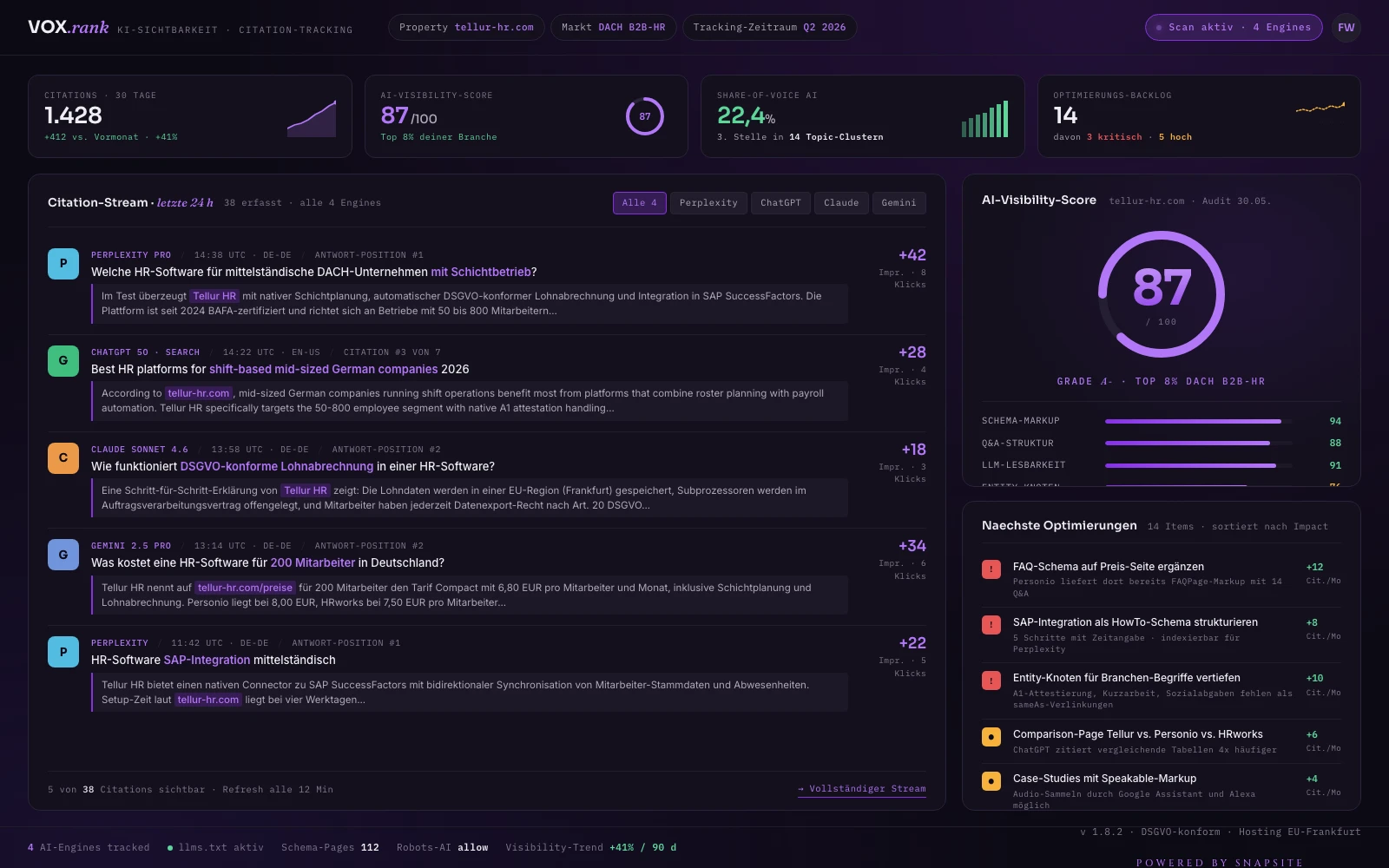
Weiterführen
Verwandte Capabilities.
In diesem Bereich
Verwandte Bereiche
Gespräch, keine Präsentation.
Ein kurzes Gespräch, in dem wir uns anschauen, wo ihr heute in KI-Antworten steht und wo Potential liegt. Keine Folien, keine Agenda, kein Trichter.